Come eseguire Apache Spark su Kubernetes in meno di 5 minuti

Strumenti come Ilum faranno molto per semplificare il processo di installazione di Apache Spark su Kubernetes. Questa guida ti guiderà, passo dopo passo, su come eseguire bene Spark sul tuo cluster Kubernetes. Con Ilum, l'implementazione, la gestione e il ridimensionamento dei cluster Apache Spark sono facili e naturali.
Introduzione
Oggi mostreremo come iniziare a utilizzare Apache Spark su K8s. Esistono molti modi per farlo, ma la maggior parte sono complessi e richiedono diverse configurazioni. Useremo Ilum poiché ciò eseguirà tutta la configurazione del cluster per noi. Nel prossimo post del blog, confronteremo l'utilizzo con l'operatore Spark.
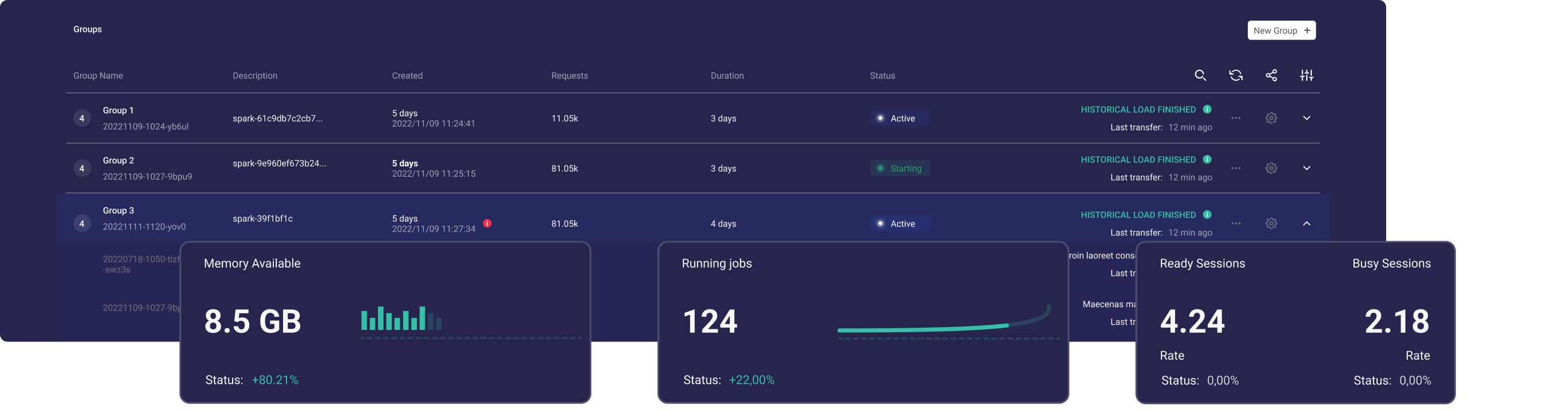
Ilum è un data lakehouse modulare e gratuito per distribuire e gestire facilmente i cluster Apache Spark. Ha una semplice API per definire e gestire Spark, gestirà tutte le dipendenze. Aiuta con la creazione del tuo spark gestito.
Con Ilum, puoi distribuire cluster Spark in pochi minuti e iniziare immediatamente a eseguire le applicazioni Spark. Ilum consente di aumentare facilmente il numero di istanze e di inserire i cluster Spark, gestendo più cluster Spark da un'unica interfaccia utente.
Con Ilum, iniziare è facile se sei relativamente nuovo ad Apache Spark su Kubernetes.
Guida passo passo per installare Apache Spark su Kubernetes
Avvio rapido
Partiamo dal presupposto che tu abbia un cluster Kubernetes attivo e funzionante, nel caso in cui non lo abbia, dai un'occhiata a queste istruzioni per configurare un cluster Kubernetes sul minikube. Controlla come installare minikube .
Configurare un cluster Kubernetes locale
- Installa Minikube: Esegui il seguente comando per installare Minikube insieme alle risorse consigliate. In questo modo verrà installato Minikube con 6 vCPU e 12288 MB di memoria, incluso il componente aggiuntivo del server delle metriche necessario per il monitoraggio.
minikube start --cpus 6 --memory 12288 --addons metrics-server Una volta che hai un cluster Kubernetes in esecuzione, bastano pochi comandi per installare Ilum:
Installa Spark su Kubernetes con Ilum
- Aggiungere Archivio dell'elmo di Ilum
Timone repo aggiungere ilum https://charts.ilum.cloud - Installa Ilum nel tuo cluster
Here we have a few options.
a) The recommended one is to start with a few additional modules turned on (Data Lineage, SQL, Data Catalog).
helm install ilum ilum/ilum \
--set ilum-hive-metastore.enabled=true \
--set ilum-core.metastore.enabled=true \
--set ilum-sql.enabled=true \
--set ilum-core.sql.enabled=true \
--set global.lineage.enabled=trueb) you can also start with the most basic option which has only Spark and Jupyter notebooks.
Installazione del timone e ile/el c) there is also an option to use ilum's module selection tool qui .
minikube ssh docker pull ilum/core:6.6.0
Questa configurazione dovrebbe richiedere circa due minuti. Ilum verrà distribuito nel cluster Kubernetes, preparandolo per gestire i processi Spark.
Una volta installato Ilum, è possibile accedere all'interfaccia utente con port-forward e localhost:9777.
- Inoltro porta all'interfaccia utente di accesso: Utilizza il port forwarding di Kubernetes per accedere all'interfaccia utente di Ilum.
kubectl port-forward svc/ilum-ui 9777:9777 Usare amministratore/amministratore come credenziali predefinite. È possibile modificarli durante il Processo di distribuzione .
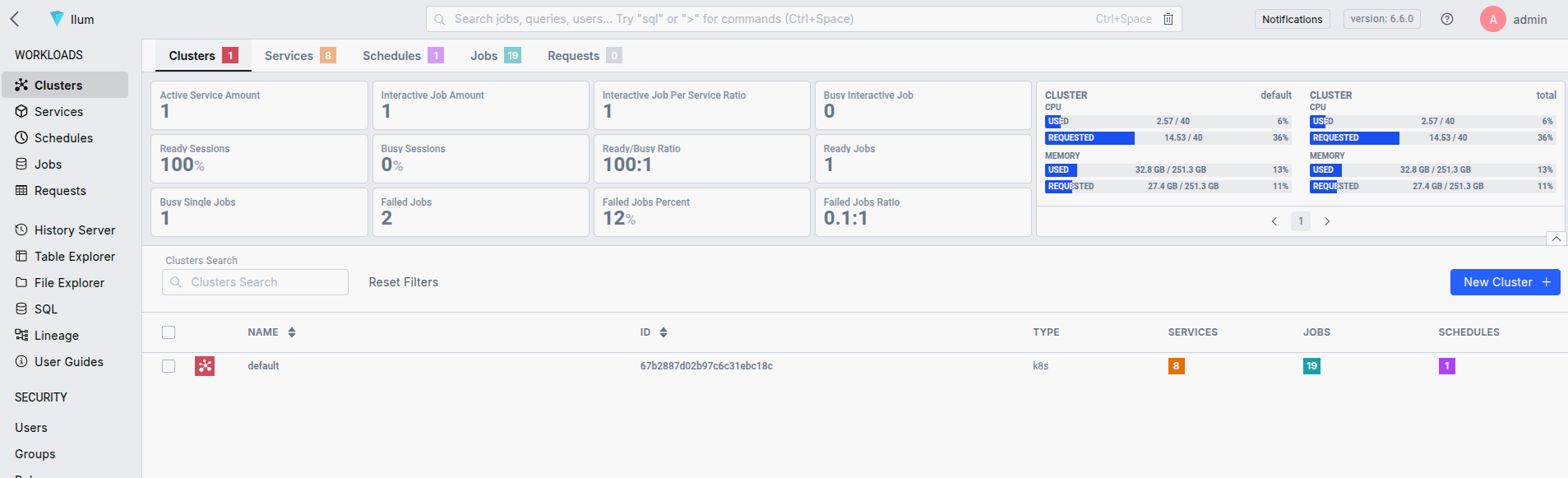
Questo è tutto, il tuo cluster Kubernetes è ora configurato per gestire i processi Spark. Ilum fornisce una semplice API e un'interfaccia utente che semplificano l'invio di applicazioni Spark. Puoi anche usare il buon vecchio Invio scintilla .
Distribuire l'applicazione Spark su Kubernetes
Iniziamo ora un semplice lavoro di scintilla. Useremo l'esempio "SparkPi" di Spark documentazione . È possibile utilizzare il file jar da questo collegamento .
ilum add spark job
Ilum creerà un pod Kubernetes del driver Spark, utilizza l'immagine docker Spark versione 3.x. È possibile controllare il numero di pod dell'executor Spark ridimensionandoli a più nodi. Questo è il modo più semplice per inviare domande di scintilla a K8s.

Eseguire Spark su Kubernetes è davvero facile e senza attriti con Ilum. Configurerà l'intero cluster e presenterà un'interfaccia in cui è possibile gestire e monitorare il cluster Spark. Crediamo che le app spark su Kubernetes siano il futuro dei big data. Con Kubernetes, le applicazioni Spark saranno in grado di gestire enormi volumi di dati in modo molto più affidabile, fornendo così informazioni esatte ed essendo in grado di guidare le decisioni con i big data.
Invio di un'applicazione Spark a Kubernetes (vecchio stile)
L'invio di un processo Spark a un cluster Kubernetes comporta l'utilizzo del scintilla-invio script con configurazioni specifiche per Kubernetes. Ecco una guida passo passo:
Passi :
-
Preparare l'applicazione Spark : crea un pacchetto dell'applicazione Spark in un file JAR (per Scala/Java) o in uno script Python.
-
Usare
scintilla-invioda distribuire : Eseguire il comandoscintilla-inviocon opzioni specifiche di Kubernetes:./bin/spark-submit \ --master k8s://https://<k8s-apiserver-host>:<k8s-apiserver-port> \ --deploy-mode cluster \ --nome spark-app \ --class org.apache.spark.examples.SparkPi \ --conf spark.executor.instances=3 \ --conf spark.kubernetes.container.image=<your-spark-image> \ local:///path/to/your-app.jarSostituire:
<k8s-apiserver-host>: l'host del server API Kubernetes.<k8s-apiserver-port>: la porta del server API Kubernetes.<your-spark-image>: l'immagine Docker contenente Spark.local:///path/to/your-app.jar: percorso del file JAR dell'applicazione all'interno dell'immagine Docker.
Configurazioni dei tasti :
--padrone: specifica l'URL dell'API Kubernetes.--deploy-mode: Impostare sugrappoloper eseguire il driver all'interno del cluster Kubernetes.--nome: assegna un nome all'applicazione Spark.--classe: Classe principale dell'applicazione.--conf spark.executor.instances: Numero di pod dell'esecutore.--conf spark.kubernetes.container.image: immagine Docker per i pod Spark.
Per maggiori dettagli, fare riferimento alla Documentazione di Apache Spark sull'esecuzione su Kubernetes .
2. Creazione di un'immagine Docker personalizzata per Spark
La creazione di un'immagine Docker personalizzata consente di creare pacchetti dell'applicazione Spark e delle relative dipendenze, garantendo la coerenza tra gli ambienti.
Passi :
-
Creare un Dockerfile : definisce l'ambiente e le dipendenze.
# Usa l'immagine di base ufficiale di Spark DA scintilla:3.5.3 # Imposta le variabili d'ambiente ENV SPARK_HOME=/opt/scintilla ENV PATH=$PATH:$SPARK_HOME/bin # Copia il file JAR dell'applicazione nell'immagine COPIA your-app.jar $SPARK_HOME/esempi/barattoli/ # Imposta il punto di ingresso per eseguire la tua applicazione ENTRYPOINT ["spark-submit", "--class", "org.apache.spark.examples.SparkPi", "--master", "local[4]", "/opt/spark/examples/jars/your-app.jar"]In questo Dockerfile:
DA scintilla:3.5.3: utilizza l'immagine ufficiale di Spark come base.ENV: imposta le variabili di ambiente per Spark.COPIARE: aggiunge il file JAR dell'applicazione all'immagine.PUNTO DI INGRESSO: definisce il comando predefinito per eseguire l'applicazione Spark.
-
Compilare l'immagine Docker : utilizza Docker per creare la tua immagine.
docker build -t tuo-repo/tua-scintilla-app:ultimo .Sostituire
il tuo-repository/la-tua-scintilla-appcon il repository Docker e il nome dell'immagine. -
Inviare l'immagine a un registro di sistema : carica l'immagine in un registro Docker accessibile dal cluster Kubernetes.
docker push il tuo-repository/la-tua-scintilla-app:più recente
Durante l'utilizzo scintilla-invio è un metodo comune per la distribuzione di applicazioni Spark, potrebbe non essere l'approccio più efficiente per gli ambienti di produzione. Gli invii manuali possono causare incongruenze e sono difficili da integrare nei flussi di lavoro automatizzati. Per migliorare l'efficienza e la manutenibilità, si consiglia di sfruttare l'API REST di Ilum.
Automazione delle distribuzioni di Spark con l'API REST di Ilum
Ilum offre una solida API RESTful che consente un'interazione senza soluzione di continuità con i cluster Spark. Questa API facilita l'automazione dell'invio, del monitoraggio e della gestione dei processi, rendendola la scelta ideale per le pipeline di integrazione continua/distribuzione continua (CI/CD).
Vantaggi dell'utilizzo dell'API REST di Ilum:
- Automazione : Integra gli invii di processi Spark nelle pipeline CI/CD, riducendo l'intervento manuale e i potenziali errori.
- Consistenza : Garantisci processi di distribuzione uniformi in diversi ambienti.
- Scalabilità : consente di gestire facilmente più cluster e processi Spark a livello di codice.
Esempio: invio di un lavoro Spark tramite l'API REST di ilum
Per inviare un processo Spark utilizzando l'API REST di Ilum, è possibile effettuare una richiesta HTTP POST con i parametri necessari. Ecco un esempio semplificato utilizzando ricciolo :
curl -X POST https://<ilum-server>/api/v1/job/submit \
-H "Tipo di contenuto: multipart/form-data" \
-F "nome=lavoro-esempio" \
-F "clusterName=predefinito" \
-F "jobClass=org.apache.spark.examples.SparkPi" \
-F "barattoli=@/percorso/di/your-app.jar" \
-F "jobConfig=spark.executor.instances=3; spark.executor.memory=4g" In questo comando:
nome: specifica il nome del processo.clusterName: indica il cluster di destinazione.classe di lavoro: definisce la classe principale dell'applicazione Spark.Vasi: carica il file JAR dell'applicazione.jobConfig: imposta le configurazioni di Spark, ad esempio il numero di esecutori e l'allocazione della memoria.
Per informazioni dettagliate sugli endpoint e sui parametri API, fare riferimento alla Documentazione dell'API Ilum .
Migliorare l'efficienza con gli Spark Job interattivi
Oltre ad automatizzare l'invio dei lavori, la trasformazione dei processi Spark in microservizi interattivi può ottimizzare in modo significativo l'utilizzo delle risorse e i tempi di risposta. Ilum supporta la creazione di sessioni Spark interattive a esecuzione prolungata in grado di elaborare dati in tempo reale senza il sovraccarico dell'inizializzazione di un nuovo contesto Spark per ogni richiesta.
Vantaggi dei lavori Spark interattivi:
- Latenza ridotta : elimina la necessità di avviare un nuovo contesto Spark per ogni processo, portando a un'esecuzione più rapida.
- Ottimizzazione delle risorse : mantiene un contesto Spark persistente, consentendo una gestione efficiente delle risorse.
- Scalabilità : gestisce più richieste contemporaneamente all'interno della stessa sessione Spark.
Per implementare un processo Spark interattivo con Ilum, è possibile definire un'applicazione Spark che ascolta i dati in arrivo e li elabora in tempo reale. Questo approccio è particolarmente vantaggioso per le applicazioni che richiedono un'elaborazione e una risposta immediata dei dati.
Per una guida completa sulla configurazione dei processi Spark interattivi e sull'ottimizzazione del cluster Spark, fare riferimento al post del blog di Ilum: Come ottimizzare il cluster Spark con i processi Spark interattivi .
Integrando l'API REST di Ilum e adottando lavori Spark interattivi, puoi semplificare i flussi di lavoro Spark, migliorare l'automazione e ottenere un ambiente di elaborazione dati più efficiente e scalabile.
Vantaggi dell'utilizzo di Ilum per eseguire Spark su Kubernetes
Ilum è dotato di un'interfaccia utente intuitiva e di un'API resiliente per scalare e gestire i cluster Spark, configurando un paio di applicazioni Spark da un'unica interfaccia. Ecco alcune fantastiche funzionalità a questo proposito:
- Facilità d'uso : Ilum semplifica la configurazione e la gestione di Spark su Kubernetes con un'interfaccia utente intuitiva di Spark, eliminando i complessi processi di configurazione.
- Distribuzione rapida: Configura, distribuisci e ridimensiona i cluster Spark in pochi minuti per accelerare i tempi di esecuzione e test delle applicazioni immediatamente.
- Scalabilità: Utilizzando l'API Kubernetes, è possibile scalare facilmente i cluster Spark verso l'alto o verso il basso per soddisfare le esigenze di elaborazione dei dati, garantendo un utilizzo ottimale delle risorse.
- Modularità : Ilum è dotato di un framework modulare che consente agli utenti di scegliere e combinare diversi componenti come Spark History Server, Apache Jupyter, Minio e molto altro.
Migrazione da Apache Hadoop Yarn
Ora che Apache Hadoop Yarn è in profonda stagnazione, sempre più organizzazioni stanno cercando di migrare da Yarn a Kubernetes. Ciò è attribuito a diversi motivi, ma il più comune è che Kubernetes fornisce una piattaforma più resiliente e flessibile in materia di gestione dei carichi di lavoro dei Big Data.
In generale, è difficile effettuare una migrazione della piattaforma di elaborazione dati da Apache Hadoop Yarn a qualsiasi altra. Ci sono molti fattori da considerare quando si effettua un tale passaggio: compatibilità dei dati, velocità e costo di elaborazione. Tuttavia, se la procedura fosse ben pianificata ed eseguita, sarebbe agevole e con successo.
Kubernetes è praticamente una scelta naturale quando si tratta di carichi di lavoro di Big Data grazie alla sua capacità intrinseca di essere in grado di scalare orizzontalmente. Tuttavia, con Hadoop Yarn, il numero di nodi nel cluster è limitato. È possibile aumentare e ridurre il numero di nodi all'interno di un cluster Kubernetes su richiesta.
Consente inoltre funzionalità che non sono disponibili in Yarn, ad esempio: autoriparazione e ridimensionamento orizzontale.
È ora di passare a Kubernetes?
Con la continua evoluzione del mondo dei big data, si evolvono anche gli strumenti e le tecnologie utilizzate per gestirli. Per anni, Apache Hadoop YARN è stato lo standard de facto per la gestione delle risorse in ambienti di big data. Ma con l'ascesa delle tecnologie di containerizzazione e orchestrazione come Kubernetes, è giunto il momento di fare il passaggio?
Kubernetes sta guadagnando popolarità come piattaforma di orchestrazione dei container, e per una buona ragione. È flessibile, scalabile e relativamente facile da usare. Se stai ancora utilizzando l'infrastruttura tradizionale basata su VM, ora potrebbe essere il momento di passare a Kubernetes.
Se stai lavorando con i container, allora dovresti assolutamente preoccuparti di Kubernetes. Può aiutarti a gestire e distribuire i tuoi container in modo più efficace ed è particolarmente utile se stai lavorando con molti container o se stai distribuendo i tuoi container su una piattaforma cloud.
Kubernetes è anche un'ottima scelta se stai cercando uno strumento di orchestrazione supportato da un'importante azienda tecnologica. Google utilizza Kubernetes da anni per gestire le proprie applicazioni containerizzate e ha investito molto tempo e risorse per renderlo un ottimo strumento.
Non c'è un chiaro vincitore nel dibattito tra YARN e Kubernetes. La soluzione migliore per la tua organizzazione dipenderà dalle tue esigenze specifiche e dai casi d'uso. Se stai cercando una soluzione di gestione delle risorse più flessibile e scalabile, vale la pena prendere in considerazione Kubernetes. Se hai bisogno di un supporto migliore per le applicazioni legacy, YARN potrebbe essere un'opzione migliore.
Qualunque piattaforma tu scelga, Ilum può aiutarti a ottenere il massimo da essa. La nostra piattaforma è progettata per funzionare sia con YARN che con Kubernetes e il nostro team di esperti può aiutarti a scegliere e implementare la soluzione giusta per la tua organizzazione.
Cluster Spark gestito
Un cluster Spark gestito è una soluzione basata sul cloud che semplifica il provisioning e la gestione dei cluster Spark. Fornisce un'interfaccia basata sul Web per la creazione e la gestione di cluster Spark, nonché un set di API per l'automazione delle attività di gestione dei cluster. I cluster Spark gestiti vengono spesso usati da data scientist e sviluppatori che desiderano effettuare rapidamente il provisioning e gestire i cluster Spark senza doversi preoccupare dell'infrastruttura sottostante.
Ilum offre la possibilità di creare e gestire il proprio cluster Spark, che può essere eseguito in qualsiasi ambiente, incluso il cloud, in locale o una combinazione di entrambi.

I vantaggi di Apache Spark su Kubernetes
C'è stato un certo dibattito sul fatto che Apache Spark debba essere eseguito su Kubernetes.
Alcune persone sostengono che Kubernetes sia troppo complesso e che Spark dovrebbe continuare a essere eseguito sul proprio gestore di cluster dedicato o rimanere nel cloud. Altri sostengono che Kubernetes sia il futuro dell'elaborazione dei big data e che Spark dovrebbe abbracciarlo.
Noi siamo in quest'ultimo campo. Crediamo che Kubernetes sia il futuro dell'elaborazione dei big data e che Apache Spark debba essere eseguito su Kubernetes.
Il più grande vantaggio dell'utilizzo di Spark su Kubernetes è che consente una scalabilità molto più semplice delle applicazioni Spark. Questo perché Kubernetes è progettato per gestire distribuzioni di un gran numero di contenitori simultanei. Quindi, se si dispone di un'applicazione Spark che deve elaborare una grande quantità di dati, è possibile distribuire semplicemente più contenitori nel cluster Kubernetes per elaborare i dati in parallelo. Questa operazione è molto più semplice rispetto alla configurazione di un nuovo cluster Spark su EMR ogni volta che è necessario aumentare l'elaborazione. Puoi eseguirlo su qualsiasi piattaforma cloud (AWS, Google Cloud, Azure, ecc.) o on-premise. Ciò significa che è possibile spostare facilmente le applicazioni Spark da un ambiente all'altro senza doversi preoccupare di cambiare il gestore cluster.
Un altro enorme vantaggio è che consente flussi di lavoro più flessibili. Ad esempio, se è necessario elaborare dati da più origini, è possibile distribuire facilmente contenitori diversi per ogni origine e farli elaborare tutti in parallelo. Questa operazione è molto più semplice rispetto al tentativo di gestire un flusso di lavoro complesso in un singolo cluster Spark.
Kubernetes dispone di diverse funzionalità di sicurezza che lo rendono un'opzione più interessante per l'esecuzione di applicazioni Spark. Ad esempio, Kubernetes supporta il controllo degli accessi in base al ruolo, che consente di ottimizzare chi ha accesso al cluster Spark.
Quindi il gioco è fatto. Questi sono solo alcuni dei motivi per cui riteniamo che Apache Spark debba essere eseguito su Kubernetes. Se non sei convinto, ti invitiamo a provarlo tu stesso. Pensiamo che rimarrai sorpreso di quanto bene funzioni.
Risorse aggiuntive
- Controlla come installare Minikube
- Documentazione di Kubernetes
- Sito ufficiale di Ilum
- Documentazione Ufficiale Ilum
- Ilum Helm Chart
Conclusione
Ilum semplifica il processo di installazione e gestione di Apache Spark su Kubernetes, rendendolo la scelta ideale sia per i principianti che per gli utenti esperti. Seguendo questa guida, avrai un cluster Spark funzionante in esecuzione su Kubernetes in pochissimo tempo.