Come ottimizzare il cluster Spark con i processi Spark interattivi

In questo articolo imparerai:
- Come ridurre il tempo di esecuzione del processo Spark
- Che cos'è un lavoro interattivo a Ilum
- Come eseguire un processo spark interattivo
- Differenze tra l'esecuzione di un processo Spark con l'API Ilum e l'API Spark
Tipi di lavoro Ilum
Ci sono tre tipi di lavori che puoi eseguire in Ilum: singolo lavoro , lavoro interattivo e codice interattivo . In questo articolo, ci concentreremo sul lavoro interattivo digitare. Tuttavia, è importante conoscere le differenze tra i tre tipi di lavoro, quindi diamo una rapida panoramica di ciascuno di essi.
Con singoli lavori , è possibile inviare programmi simili al codice. Consentono di inviare un'applicazione Spark al cluster, con codice precompilato, senza interazione durante il runtime. In questa modalità, è necessario inviare un jar compilato a Ilum, che viene utilizzato per avviare un singolo lavoro. Puoi inviarlo direttamente oppure puoi utilizzare le credenziali AWS per ottenerlo da un bucket S3. Un esempio tipico di utilizzo di un singolo processo potrebbe essere un tipo di attività di preparazione dei dati.
Ilum fornisce anche un interattivo Modalità codice , che consente di inviare comandi in fase di esecuzione. Ciò è utile per le attività in cui è necessario interagire con i dati, ad esempio l'analisi esplorativa dei dati.
Lavoro interattivo
I processi interattivi hanno sessioni a esecuzione prolungata, in cui è possibile inviare i dati dell'istanza del processo da eseguire immediatamente. La caratteristica principale di tale modalità è che non è necessario attendere l'inizializzazione del contesto spark. Se gli utenti puntano allo stesso ID processo, interagirebbero con lo stesso contesto Spark. Ilum avvolge la logica dell'applicazione Spark in un processo Spark a esecuzione prolungata in grado di gestire immediatamente le richieste di calcolo, senza la necessità di attendere l'inizializzazione del contesto Spark.
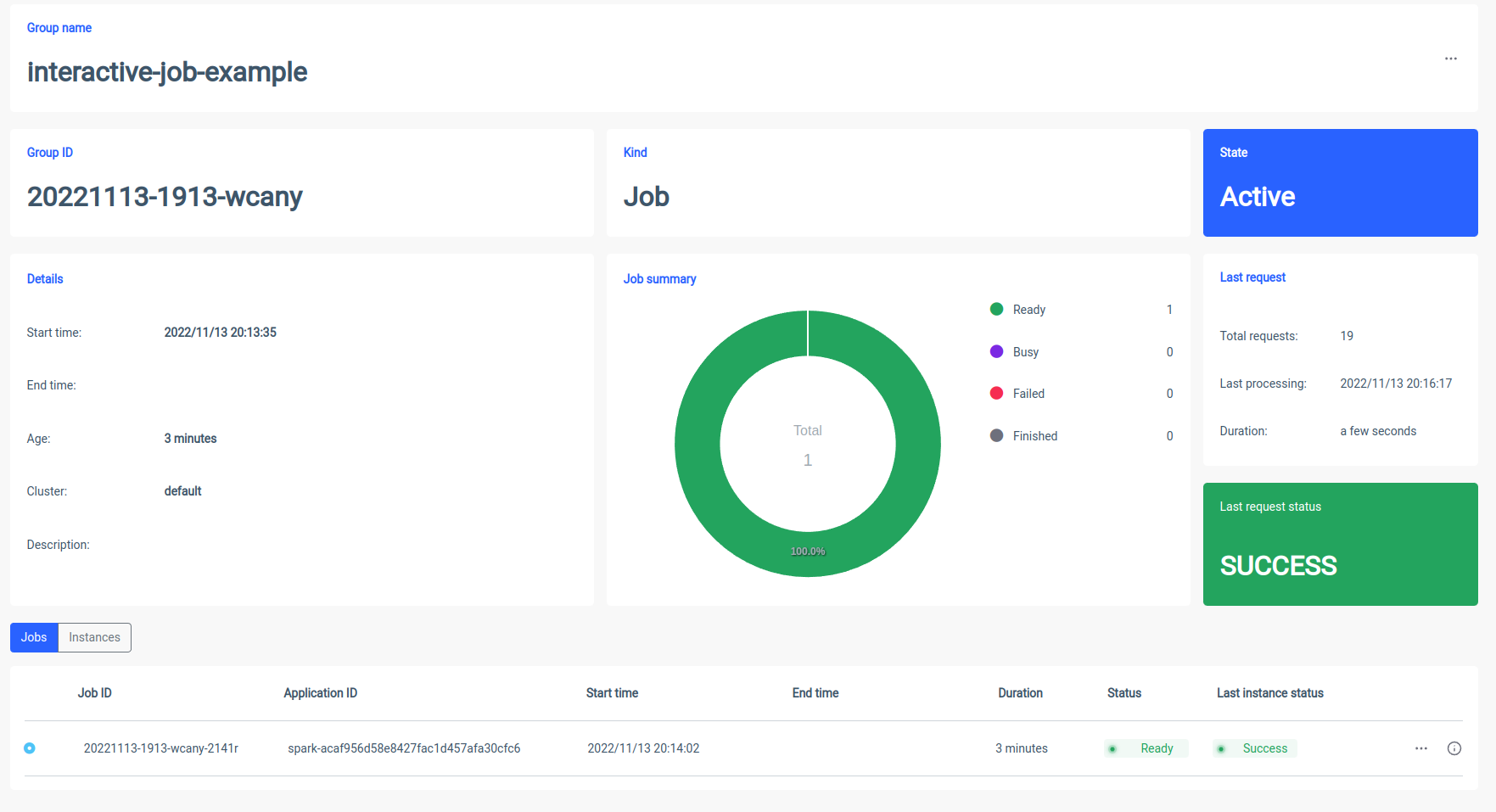
Avvio di un processo interattivo
Diamo un'occhiata a come si può avviare la sessione interattiva di Ilum. La prima cosa che dobbiamo fare è configurare Ilum. Puoi farlo facilmente con il minikube. Un tutorial con l'installazione di Ilum è disponibile sotto questo collegamento . Nel passaggio successivo, dobbiamo creare un file jar che contiene un'implementazione dell'interfaccia di lavoro di Ilum. Per utilizzare l'API del processo Ilum, dobbiamo aggiungerla al progetto con alcuni gestori delle dipendenze, come Maven o Gradle. In questo esempio, utilizzeremo del codice Scala con un Gradle per calcolare il PI.
L'esempio completo è disponibile sul nostro sito GitHub .
Se preferisci non costruirlo da solo, puoi trovare il file jar compilato qui .
Il primo passo è creare una cartella per il nostro progetto e cambiare la directory in essa.
$ mkdir esempio-di-lavoro-interattivo
$ cd esempio-di-lavoro-interattivo Se non hai installato la versione più recente di Gradle sul tuo computer, puoi controllare come farlo qui . Quindi esegui il seguente comando in un terminale dall'interno della directory del progetto:
$ gradle init Scegli un'applicazione Scala con Groovy come DSL. L'output dovrebbe essere simile al seguente:
Avvio di un Gradle Daemon (le build successive saranno più veloci)
Seleziona il tipo di progetto da generare:
1: base
2: Applicazione
3: Biblioteca
4: Plugin Gradle
Entra nella selezione (default: base) [1..4] 2
Seleziona la lingua di implementazione:
1: C++
2: Groovy
3: Giava
4: Kotlin
5: Scala
6: Veloce
Inserisci la selezione (default: Java) [1..6] 5
Suddividere le funzionalità in più sottoprogetti?:
1: No - un solo progetto di applicazione
2: Sì - Progetti di applicazioni e librerie
Inserire la selezione (default: no - solo un progetto applicativo) [1..2] 1
Selezionare lo script di compilazione DSL:
1: Groovy
2: Kotlin
Inserisci la selezione (default: Groovy) [1..2] 1
Generare build utilizzando nuove API e comportamento (alcune funzionalità potrebbero cambiare nella prossima versione secondaria)? (predefinito: no) [sì, no] no
Nome del progetto (predefinito: interactive-job-example):
Pacchetto sorgente (predefinito: interactive.job.example):
> Compito :init
Ottieni ulteriore assistenza per il tuo progetto: https://docs.gradle.org/7.5.1/samples/sample_building_scala_applications_multi_project.html
COSTRUISCI CON SUCCESSO NEGLI ANNI '30
2 attività attuabili: 2 eseguite Ora dobbiamo aggiungere il repository Ilum e le dipendenze necessarie nel tuo build.gradle file. In questo tutorial, useremo Scala 2.12.
dipendenze {
implementazione 'org.scala-lang:scala-library:2.12.16'
Implementazione 'cloud.ilum:ilum-job-api:5.0.1'
compileOnly 'org.apache.spark:spark-sql_2.12:3.1.2'
} Ora possiamo creare una classe Scala che estende il Job di Ilum e che calcola PI:
pacchetto interactive.job.example
import cloud.ilum.job.Job
importare org.apache.spark.sql.SparkSession
import scala.math.random
class InteractiveJobExample estende il lavoro {
override def run(sparkSession: SparkSession, config: Map[String, Qualsiasi]): Option[String] = {
val slices = config.getOrElse("slices", "2").toString.toInt
val n = math.min(100000L * fette, Int.MaxValue).toInt
val count = sparkSession.sparkContext.parallelize(1 fino a n, fette).map { i =>
val x = casuale * 2 - 1
val y = casuale * 2 - 1
if (x * x + y * y <= 1) 1 else 0
}.riduci(_ + _)
Alcuni"Pi è circa ${4.0 * count / (n - 1)}")
}
} Se Gradle ha generato alcune classi principali o di test, basta rimuoverle dal progetto e creare una build.
$ gradle costruire Il file jar generato dovrebbe essere in ' ./esempio-lavoro-interattivo/app/build/libs/app.jar ', possiamo quindi tornare a Ilum. Una volta che tutti i pod sono in esecuzione, crea un port forward per ilum-ui:
kubectl port-forward svc/ilum-ui 9777:9777 Apri l'interfaccia utente di Ilum nel tuo browser e crea un nuovo gruppo:
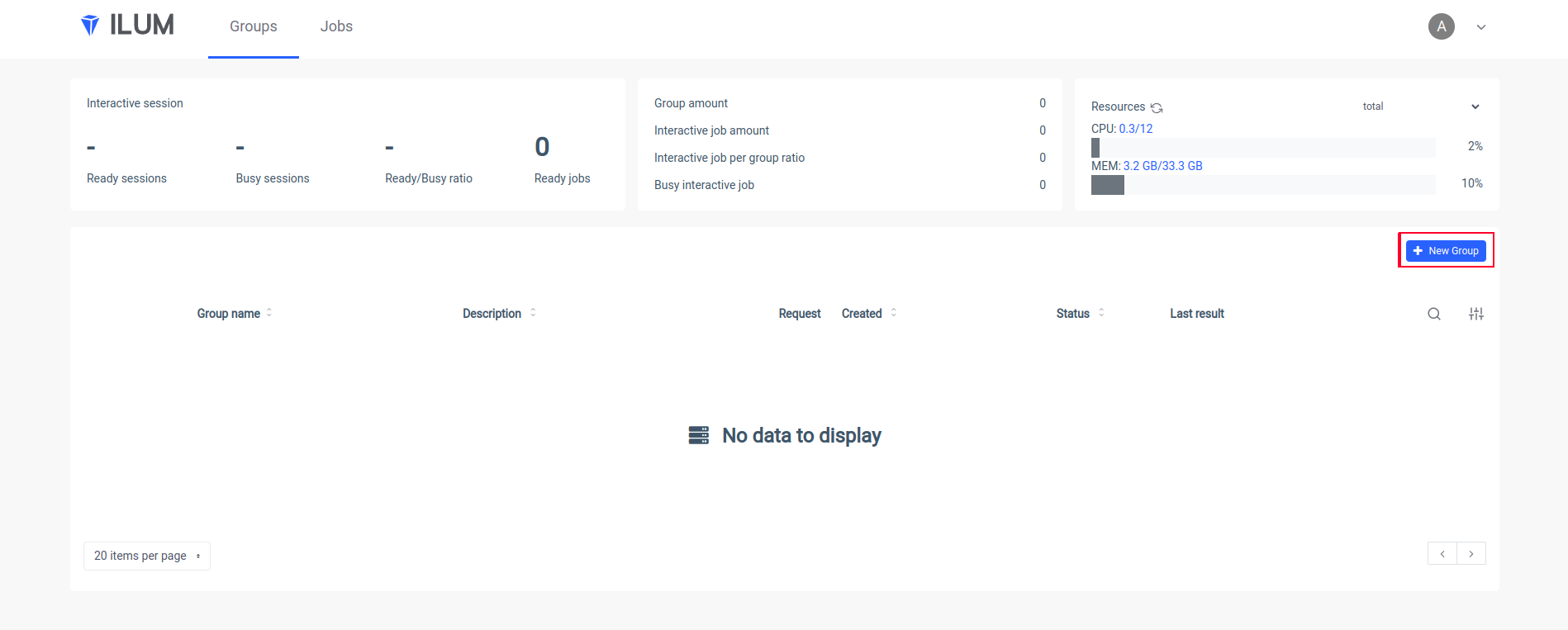
Inserisci un nome di un gruppo, scegli o crea un cluster, carica il tuo file jar e applica le modifiche:
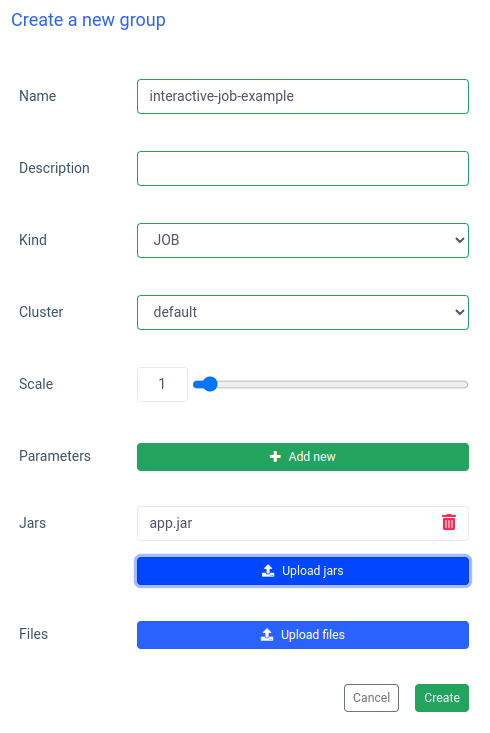
Ilum creerà un pod driver Spark e sarà possibile controllare il numero di pod dell'executor Spark ridimensionandoli. Dopo che il contenitore spark è pronto, eseguiamo i processi:
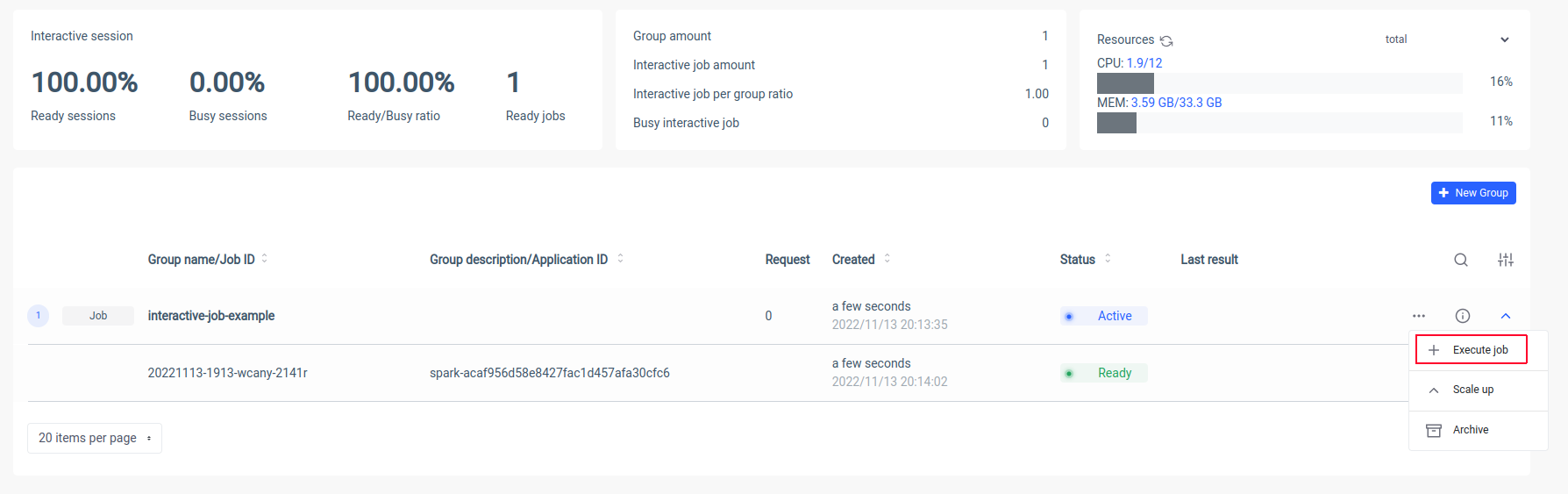
Ora dobbiamo mettere il nome canonico della nostra classe Scala
interactive.job.example.InteractiveJobExample e definisci il parametro slices in formato JSON:
{
"config": {
"slices": "10"
}
} Dovresti vedere il risultato subito dopo l'inizio del lavoro
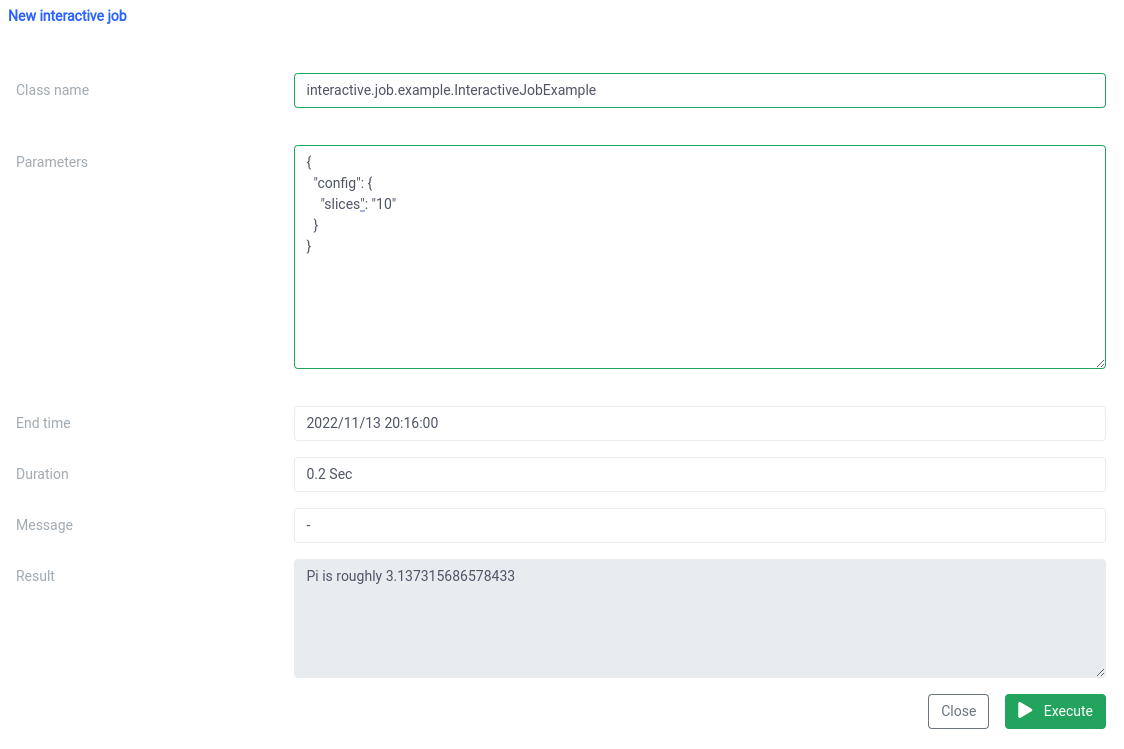
È possibile modificare i parametri ed eseguire nuovamente un lavoro e i calcoli verranno eseguiti sul posto.
Confronto interattivo e singolo lavoro
In Ilum è anche possibile eseguire un singolo processo. La differenza più importante rispetto alla modalità interattiva è che non è necessario implementare l'API del processo. Possiamo utilizzare il jar SparkPi dagli esempi di Spark:
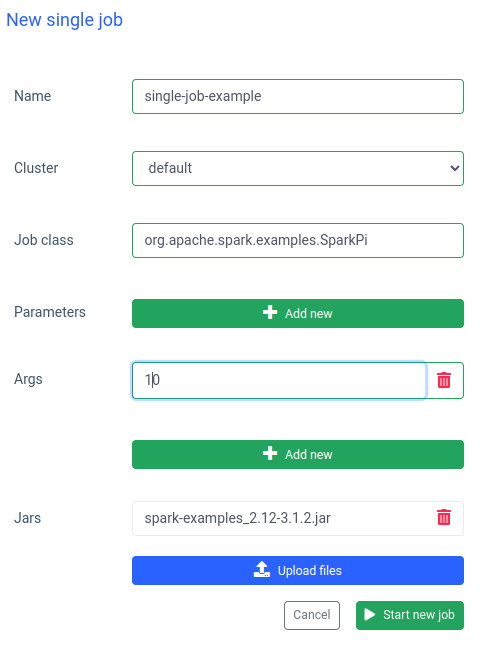
Anche l'esecuzione di un lavoro di questo tipo è veloce, ma i lavori interattivi lo sono 20 volte più veloce (4 secondi contro 200 ms) . Se si desidera avviare un lavoro simile con altri parametri, sarà necessario preparare un nuovo lavoro e caricare nuovamente il jar.
Confronto tra Ilum e Apache Spark semplice
Ho configurato Apache Spark localmente con un bitnami/scintilla Immagine docker. Se si desidera eseguire anche Spark sul computer, è possibile utilizzare docker-compose:
$ ricciolo -LO https://raw.githubusercontent.com/bitnami/containers/main/bitnami/spark/docker-compose.yml
$ docker-compose su Una volta che Spark è in esecuzione, dovresti essere in grado di andare su localhost:8080 e vedere l'interfaccia utente di amministrazione. Dobbiamo ottenere l'URL di Spark dal browser:

Quindi, dobbiamo aprire il contenitore Spark in modalità interattiva utilizzando
$ docker exec -it <containerid> -- bash 
E ora all'interno del contenitore, possiamo inviare il processo sparkPi. In questo caso, utilizzerò SparkiPi dal jar degli esempi e, come parametro principale, inserirà l'URL dal browser:
$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi\
--master spark://78c84485d233:7077 \
/opt/bitnami/spark/esempi/barattoli/spark-examples_2.12-3.3.0.jar\
10 Sommario
Come puoi vedere nell'esempio sopra, puoi evitare la complicata configurazione e installazione del tuo client Spark utilizzando Ilum. Ilum si occupa del lavoro e ti fornisce un'interfaccia semplice e conveniente. Inoltre, ti consente di superare i limiti di Apache Spark, che può richiedere molto tempo per l'inizializzazione. Se devi eseguire molte esecuzioni di lavori con logica simile ma parametri diversi e desideri che i calcoli vengano eseguiti immediatamente, dovresti assolutamente utilizzare la modalità di lavoro interattiva.

Somiglianze con Apache Livy
Ilum è uno strumento nativo del cloud per la gestione delle distribuzioni di Apache Spark su Kubernetes. È simile ad Apache Livy in termini di funzionalità: può controllare una sessione Spark tramite API REST e creare un'interazione in tempo reale con un cluster Spark. Tuttavia, Ilum è progettato specificamente per ambienti moderni e nativi del cloud.
Abbiamo usato Apache Livy in passato, ma abbiamo raggiunto il punto in cui Livy non era adatto agli ambienti moderni. Livio è obsoleto rispetto a Ilum. Nel 2018 abbiamo iniziato a spostare tutti i nostri ambienti su Kubernetes e abbiamo dovuto trovare un modo per distribuire, monitorare e mantenere Apache Spark su Kubernetes. Questa è stata l'occasione perfetta per costruire Ilum.