Distribuzione del microservizio PySpark su Kubernetes: rivoluzionare i data lake con Ilum.

Saluti appassionati di Ilum e fan di Python! Siamo entusiasti di svelare una nuova funzionalità tanto attesa che è destinata a potenziare il tuo percorso di scienza dei dati: il supporto completo di Python in Ilum. Per chi opera nel mondo dei dati, Python e Apache Spark sono stati a lungo un duo iconico, in grado di gestire senza problemi grandi volumi di dati e calcoli complessi. E ora, con l'ultimo aggiornamento di Ilum, puoi sfruttare la potenza di Python direttamente all'interno del tuo ambiente di data lake preferito.
Questo post del blog è la tua visita guidata all'esplorazione di questa funzione. Inizieremo con un semplice lavoro Apache Spark scritto in Python, lo eseguiremo su Ilum e poi approfondiremo. Trasformeremo il codice iniziale per supportare una modalità interattiva, offrendoti l'accesso diretto al processo Spark tramite l'API di Ilum. Alla fine di questo percorso, avrai un microservizio basato su Python che risponde alle chiamate API, il tutto in esecuzione senza problemi su Ilum.
Allora, sei pronto a migliorare il tuo gioco di dati con Python e Ilum? Iniziamo.
Tutti gli esempi sono disponibili sul nostro sito Repository GitHub .
Passaggio 1: Scrittura di un semplice lavoro Apache Spark in Python.
Prima di intraprendere il nostro viaggio in Python con Ilum, dobbiamo assicurarci che il nostro ambiente sia ben attrezzato. Per eseguire un processo Spark, è necessario che siano installati Ilum e PySpark. È possibile usare pip, il programma di installazione del pacchetto Python, per configurare PySpark. Assicurati di utilizzare Python >=3.9.
pip installare pyspark Per la configurazione e l'accesso a Ilum, si prega di seguire le linee guida fornite qui .
1.1 Esempio di SparkPi.
Ora, tuffiamoci nella scrittura del nostro lavoro Spark. Inizieremo con un semplice esempio di SparkPi
Importa sistema
da importazione casuale casuale
dall'operatore import add
da pyspark.sql importare SparkSession
if __name__ == "__main__":
scintilla = SparkSession \
.muratore\
.appName("Pipi") \
.getOrCreate()
partizioni = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partizioni
def f(_: int) -> float:
x = casuale() * 2 - 1
y = casuale() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partizioni).map(f).reduce(add)
print("Pi è circa %f" % (4,0 * conteggio / n))
scintilla.stop() Salva questo script con nome ilum_python_simple.py
Con il nostro processo Spark pronto, è il momento di eseguirlo su Ilum. Ilum offre la possibilità di inviare processi utilizzando l'interfaccia utente di Ilum o tramite l'API REST.
Iniziamo con l'interfaccia utente con il Funzione di lavoro singolo.
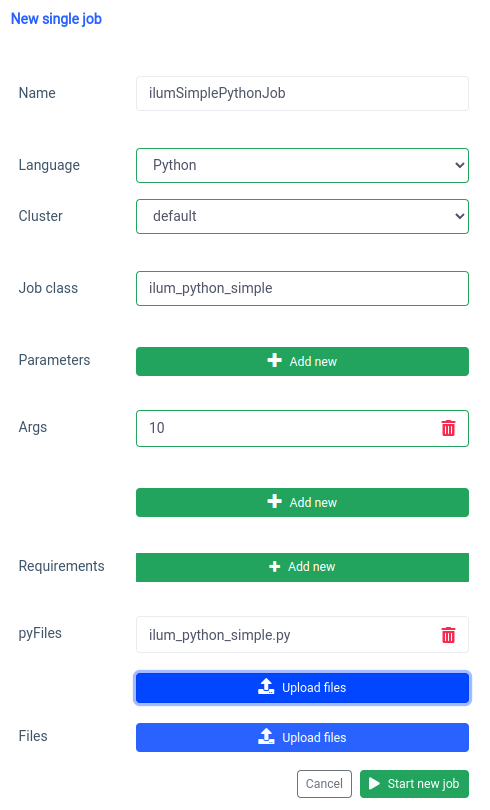
Possiamo ottenere la stessa cosa con il API , ma prima dobbiamo esporre l'API ilum-core con il port forward.
kubectl port-forward svc/ilum-core 9888:9888 Con la porta esposta possiamo effettuare una chiamata API.
curl -X POST 'localhost:9888/api/v1/job/submit' \
--form 'nome="ilumSimplePythonJob"' \
--form 'clusterName="default"' \
--form 'jobClass="ilum_python_simple"' \
--form 'args="10"' \
--form 'pyFiles=@"/percorso/di/ilum_python_simple.py"' \
--form 'linguaggio="PYTHON"' Chiamata API
Di conseguenza, riceveremo l'ID del lavoro creato.
{"jobId":"20230724-1154-m78f3gmlo5j"} Risultato
Per controllare i log del lavoro possiamo effettuare una chiamata API a
curl localhost:9888/api/v1/lavoro/20230724-1154-m78f3gmlo5j/logs Chiamata API
E questo è tutto! Hai scritto ed eseguito un semplice processo Python Spark su Ilum. Diamo un'occhiata a un esempio un po' più avanzato che richiede librerie Python aggiuntive.
1.2 Esempio di lavoro con numpy.
In questa sezione, esamineremo un esempio pratico di un lavoro Spark scritto in Python. Questo lavoro prevede la lettura di un set di dati, l'elaborazione, l'addestramento di un modello di Machine Learning su di esso e il salvataggio delle previsioni. Useremo un Tel-churn.csv file, che puoi trovare nel nostro Repository GitHub . Per semplificare le cose, abbiamo caricato questo file in un bucket denominato ilum-files nell'istanza integrata di MinIO, che è automaticamente accessibile dall'istanza Ilum. Ciò significa che non dovrai preoccuparti di configurare alcun accesso per questo esempio: Ilum ha tutto sotto controllo. Tuttavia, se desideri recuperare dati da un bucket diverso o utilizzare Amazon S3 nei tuoi progetti, dovrai configurare gli accessi di conseguenza.
Ora che i dati sono pronti, iniziamo a scrivere il nostro processo Spark in Python. Di seguito è riportato l'esempio di codice completo:
da pyspark.sql importare SparkSession
da pyspark.ml importazione Pipeline
da pyspark.ml.feature importa StringIndexer, VectorAssembler
da pyspark.ml.classification import LogisticRegression
if __name__ == "__main__":
scintilla = SparkSession \
.muratore\
.appName("IlumAdvancedPythonExample") \
.getOrCreate()
df = spark.read.csv('s3a://ilum-files/Tel-churn.csv', header=True, inferSchema=True)
categoricalColumns = ['genere', 'Partner', 'Dipendenti', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV',
'StreamingMovies', 'Contratto', 'Fatturazione senza carta', 'Metodo di pagamento']
fasi = []
per categoricalCol in categoricalColumns:
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
stages += [stringIndexer]
label_stringIdx = StringIndexer(inputCol="Abbandona", outputCol="etichetta")
fasi += [label_stringIdx]
numericCols = ['Anziano', 'Titolari', 'Spese mensili']
assemblerInputs = [c + "Indice" per c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
Fasi += [Assemblatore]
pipeline = Pipeline(stages=stages)
pipelineModel = pipeline.fit(df)
df = pipelineModel.transform(df)
treno, test = df.randomSplit([0.7, 0.3], seme=42)
lr = LogisticRegression(featuresCol="features", labelCol="label", maxIter=10)
lrModel = lr.fit(treno)
previsioni = lrModel.transform(test)
predictions.select("customerID", "label", "prediction").show(5)
predictions.select("customerID", "label", "prediction").write.option("header", "true") \
.csv('s3a://ilum-files/predictions')
scintilla.stop() Immergiamoci nel codice:
da pyspark.sql importare SparkSession
da pyspark.ml importazione Pipeline
da pyspark.ml.feature importa StringIndexer, VectorAssembler
da pyspark.ml.classification import LogisticRegression In questo caso, stiamo importando i moduli PySpark necessari per creare una sessione Spark, creare una pipeline di Machine Learning, pre-elaborare i dati ed eseguire un modello di regressione logistica.
scintilla = SparkSession \
.muratore\
.appName("IlumAdvancedPythonExample") \
.getOrCreate() Inizializziamo un Sessione scintilla , che è il punto di ingresso a qualsiasi funzionalità di Spark. Qui è dove impostiamo il nome dell'applicazione che apparirà nell'interfaccia utente web di Spark.
df = spark.read.csv('s3a://ilum-files/Tel-churn.csv', header=True, inferSchema=True) Stiamo leggendo un file CSV archiviato in un bucket minio. Le header=Vero indica a Spark di utilizzare la prima riga del file CSV come intestazioni, mentre inferSchema=Vero fa in modo che Spark determini automaticamente il tipo di dati di ogni colonna.
categoricalColumns = ['genere', 'Partner', 'Dipendenti', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV',
'StreamingMovies', 'Contratto', 'Fatturazione senza carta', 'Metodo di pagamento'] Specifichiamo le colonne dei nostri dati che sono categoriche. Questi verranno trasformati in un secondo momento utilizzando un oggetto StringIndexer.
fasi = []
per categoricalCol in categoricalColumns:
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
stages += [stringIndexer] In questo caso, stiamo iterando l'elenco delle colonne categoriche e creando un StringIndexer per ognuna. Gli StringIndexer codificano le colonne stringa categoriche in una colonna di indici. La colonna dell'indice trasformata verrà denominata con l'aggiunta del nome della colonna originale con l'aggiunta di "Indice".
numericCols = ['Anziano', 'Titolari', 'Spese mensili']
assemblerInputs = [c + "Indice" per c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
Fasi += [Assemblatore] Qui prepariamo i dati per il nostro modello di machine learning. Creiamo un VectorAssembler che prenderà tutte le nostre colonne di funzionalità (sia categoriche che numeriche) e le assemblerà in un'unica colonna vettoriale. Questo è un requisito per la maggior parte degli algoritmi di apprendimento automatico in Spark.
treno, test = df.randomSplit([0.7, 0.3], seme=42) Abbiamo suddiviso i nostri dati in un set di addestramento e un set di test, con il 70% dei dati per il training e il restante 30% per il test.
lr = LogisticRegression(featuresCol="features", labelCol="label", maxIter=10)
lrModel = lr.fit(treno) Eseguiamo il training di un modello di regressione logistica sui dati di training.
previsioni = lrModel.transform(test)
predictions.select("customerID", "label", "prediction").show(5)
predictions.select("customerID", "label", "prediction").write.option("header", "true") \
.csv('s3a://ilum-files/predictions') Infine, usiamo il nostro modello addestrato per fare previsioni sul nostro set di test, visualizzando le prime 5 previsioni. Quindi scriviamo queste previsioni nel nostro bucket minio.
Salva questo script con nome ilum_python_advanced.py
pyspark.ml utilizza numpy come dipendenza che non è installata come impostazione predefinita, quindi dobbiamo specificarlo come requisito.
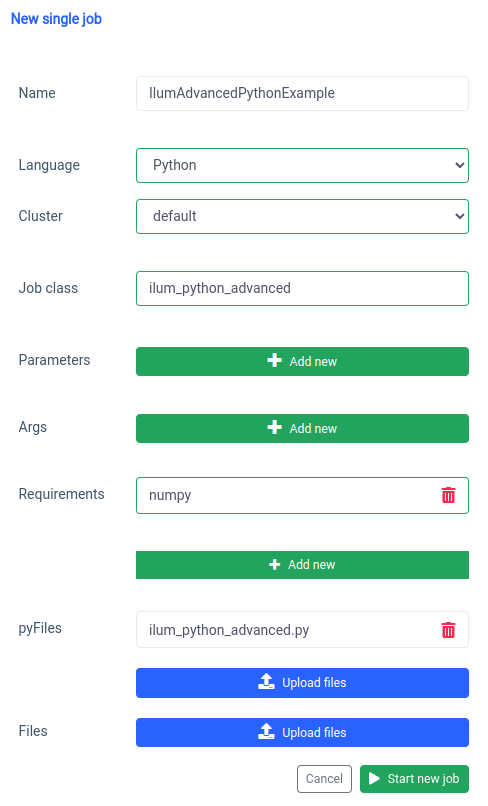
E la stessa cosa può essere fatta tramite l'API.
curl -X POST 'localhost:9888/api/v1/job/submit' \
--form 'name="IlumAdvancedPythonExample"' \
--form 'clusterName="default"' \
--form 'jobClass="ilum_python_advanced"' \
--form 'pyRequirements="numpy"' \
--form 'pyFiles=@"/percorso/di/ilum_python_advanced.py"' \
--form 'linguaggio="PYTHON"' Chiamata API
Nelle prossime sezioni, trasformeremo entrambi gli script Python in un interattivo Spark job, sfruttando appieno le capacità di Ilum.
Passaggio 2: passaggio alla modalità interattiva
La modalità interattiva è una funzionalità interessante che rende lo sviluppo di Spark più dinamico, dandoti la possibilità di eseguire, interagire e controllare i tuoi processi Spark in tempo reale. È progettato per coloro che cercano un controllo più diretto sulle proprie applicazioni Spark.
Pensa alla modalità interattiva come a una conversazione diretta con il tuo processo Spark. È possibile inserire dati, richiedere trasformazioni e recuperare risultati, il tutto in tempo reale. Ciò migliora drasticamente l'agilità e la capacità della pipeline di elaborazione dei dati, rendendola più adattabile e reattiva ai requisiti in continua evoluzione.
Ora che abbiamo familiarità con la creazione di un lavoro Spark di base in Python, facciamo un ulteriore passo avanti trasformando il nostro lavoro in uno interattivo in grado di sfruttare le capacità in tempo reale di Ilum.
2.1 Esempio di SparkPi.
Per illustrare come passare il nostro lavoro alla modalità interattiva, modificheremo il nostro precedente ilum_python_simple.py copione.
da importazione casuale casuale
dall'operatore import add
da ilum.api import IlumJob
classe SparkPiInteractiveExample(IlumJob):
def run(auto, scintilla, configurazione):
partizioni = int(config.get('partizioni', '5'))
n = 100000 * partizioni
def f(_: int) -> float:
x = casuale() * 2 - 1
y = casuale() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partizioni).map(f).reduce(add)
return "Pi è circa %f" % (4,0 * conteggio / n) Salva con nome ilum_python_simple_interactive.py
Ci sono solo alcune differenze rispetto allo SparkPi originale.
1. Pacchetto Ilum
Per iniziare, importiamo il IlumJob dal pacchetto ilum, che funge da classe base per il nostro lavoro interattivo.
La logica del processo Spark è incapsulata in una classe che si estende IlumJob , in particolare nell'ambito del suo Correre metodo. Possiamo aggiungere il pacchetto ilum con:
pip installare ilum 2. Processo Spark in una classe
La logica del processo Spark è incapsulata in una classe che si estende IlumJob , in particolare nell'ambito del suo Correre metodo.
classe SparkPiInteractiveExample(IlumJob):
def run(auto, scintilla, configurazione):
# Logica del lavoro qui Il wrapping della logica del processo in una classe è essenziale per il framework Ilum per gestire il processo e le relative risorse. In questo modo il processo viene reso anche stateless e riutilizzabile.
3. I parametri vengono gestiti in modo diverso:
Stiamo prendendo tutti gli argomenti dal dizionario di configurazione
partizioni = int(config.get('partizioni', '5')) Questo spostamento consente un passaggio dei parametri più dinamico e si integra con la gestione della configurazione di Ilum.
4. Il risultato viene restituito invece di essere stampato:
Il risultato viene restituito dal metodo Correre metodo.
return "Pi è circa %f" % (4,0 * conteggio / n) Restituendo il risultato, Ilum può gestirlo in modo più flessibile. Ad esempio, Ilum potrebbe serializzare il risultato e renderlo accessibile tramite una chiamata API.
5. Non è necessario gestire manualmente la sessione Spark
Ilum gestisce la sessione Spark per noi. Viene iniettato automaticamente nel Correre e non abbiamo bisogno di fermarlo manualmente.
def run(auto, scintilla, configurazione): Queste modifiche evidenziano la transizione da un processo Spark autonomo a un processo Ilum interattivo. L'obiettivo è migliorare la flessibilità e la riutilizzabilità del lavoro, rendendolo più adatto per calcoli dinamici, interattivi e al volo.
L'aggiunta di un processo spark interattivo viene gestita con la funzione 'new group'.
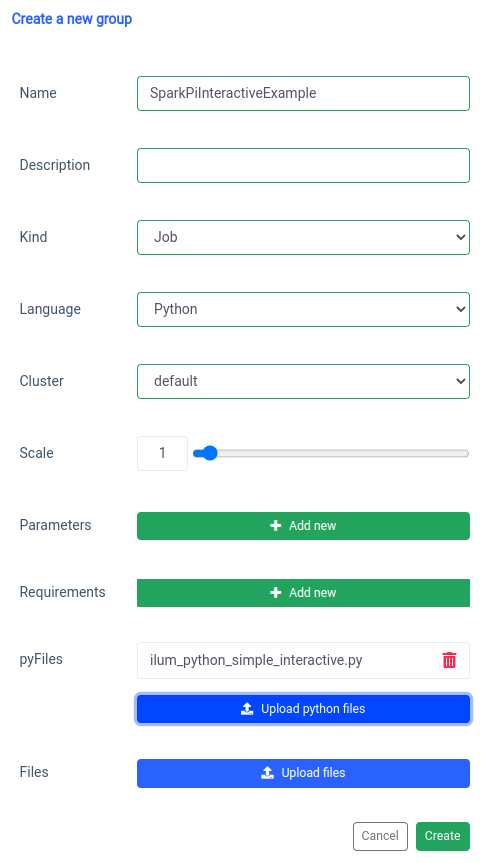
E l'esecuzione con la funzione di lavoro interattiva sull'interfaccia utente.
Il nome della classe deve essere specificato come pythonFileName.PythonClassImplementingIlumJob
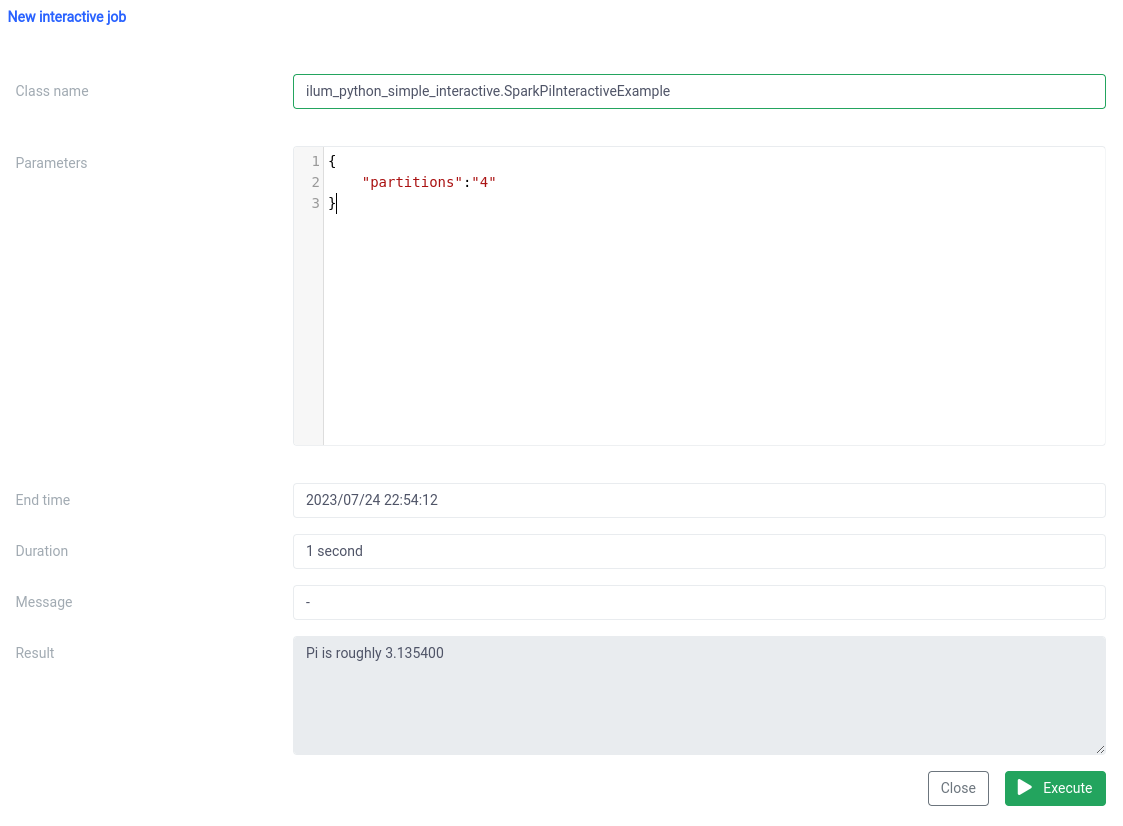
Possiamo ottenere la stessa cosa con il API .
1. Creazione del gruppo
curl -X POST 'localhost:9888/api/v1/group' \
--form 'name="SparkPiInteractiveExample"' \
--form 'kind="JOB"' \
--form 'clusterName="default"' \
--form 'pyFiles=@"/percorso/di/ilum_python_simple_interactive.py"' \
--form 'linguaggio="PYTHON"' Chiamata API
{"groupId":"20230726-1638-mjrw3"} Risultato
2. Esecuzione del processo
curl -X POST 'localhost:9888/api/v1/group/20230726-1638-mjrw3/job/execute' \
-H 'Tipo di contenuto: application/json' \
-d '{ "jobClass":"ilum_python_simple_interactive. SparkPiInteractiveExample", "jobConfig": {"partitions":"10"}, "type":"interactive_job_execute"}' Chiamata API
{
"jobInstanceId":"20230726-1638-mjrw3-a1srahhu",
"jobId":"20230726-1638-mjrw3-wwt5a",
"groupId":"20230726-1638-mjrw3",
"startTime":1690390323154,
"endTime":1690390325200,
"jobClass":"ilum_python_simple_interactive. SparkPiInteractiveExample",
"jobConfig":{
"partizioni":"10"
},
"result":"Pi greco è circa 3,149400",
"errore":null
} Risultato
2.2 Esempio di lavoro con numpy.
Diamo un'occhiata al nostro secondo esempio.
da pyspark.sql importare SparkSession
da pyspark.ml importazione Pipeline
da pyspark.ml.feature importa StringIndexer, VectorAssembler
da pyspark.ml.classification import LogisticRegression
da ilum.api import IlumJob
classe LogisticRegressionJobExample(IlumJob):
def run(self, spark_session: SparkSession, config: dict) -> str:
df = spark_session.read.csv(config.get('inputFilePath', 's3a://ilum-files/Tel-churn.csv'), header=Vero,
inferSchema=Vero)
categoricalColumns = ['genere', 'Partner', 'Dipendenti', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV',
'StreamingMovies', 'Contratto', 'Fatturazione senza carta', 'Metodo di pagamento']
fasi = []
per categoricalCol in categoricalColumns:
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
stages += [stringIndexer]
label_stringIdx = StringIndexer(inputCol="Abbandona", outputCol="etichetta")
fasi += [label_stringIdx]
numericCols = ['Anziano', 'Titolari', 'Spese mensili']
assemblerInputs = [c + "Indice" per c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
Fasi += [Assemblatore]
pipeline = Pipeline(stages=stages)
pipelineModel = pipeline.fit(df)
df = pipelineModel.transform(df)
treno, test = df.randomSplit([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))],
seed=int(config.get('seme', '42')))
lr = LogisticRegression(featuresCol="features", labelCol="label", maxIter=int(config.get('maxIter', '5')))
lrModel = lr.fit(treno)
previsioni = lrModel.transform(test)
return '{}'.format(predictions.select("customerID", "label", "prediction").limit(
int(config.get('rowLimit', '5'))).toJSON().collect()) 1. Concludiamo il lavoro in una classe, proprio come nell'esempio precedente:
classe LogisticRegressionJobExample(IlumJob):
def run(self, spark_session: SparkSession, config: dict) -> str:
# Logica del lavoro qui Anche in questo caso, la logica del processo è incapsulata nel Correre metodo di una classe che si estende IlumJob , aiutando Ilum a gestire il lavoro in modo efficiente.
2. Tutti i parametri, inclusi quelli per la pipeline di dati (come i percorsi dei file e gli iperparametri di regressione logistica), sono ottenuti dal configurazione dizionario:
df = spark_session.read.csv(config.get('inputFilePath', 's3a://ilum-files/Tel-churn.csv'), header=True, inferSchema=True)
treno, test = df.randomSplit([float(config.get('splitX', '0.7')), float(config.get('splitY', '0.3'))], seed=int(config.get('seme', '42')))
lr = LogisticRegression(featuresCol="features", labelCol="label", maxIter=int(config.get('maxIter', '5'))) Centralizzando tutti i parametri in un unico posto, Ilum fornisce un modo uniforme e coerente di configurare e ottimizzare il lavoro.
Il risultato del processo, anziché essere scritto in una posizione specifica, viene restituito come stringa JSON:
return '{}'.format(predictions.select("customerID", "label", "prediction").limit(int(config.get('rowLimit', '5'))).toJSON().collect()) Ciò consente una gestione più dinamica e flessibile del risultato del lavoro, che potrebbe quindi essere ulteriormente elaborato o esposto tramite un'API, a seconda delle esigenze dell'applicazione.
Questo codice mostra perfettamente come possiamo integrare perfettamente i processi PySpark con Ilum per abilitare pipeline di elaborazione dei dati interattive e basate su API. Da semplici esempi come l'approssimazione Pi greco a casi più complessi come la regressione logistica, i lavori interattivi di Ilum sono versatili, adattabili ed efficienti.
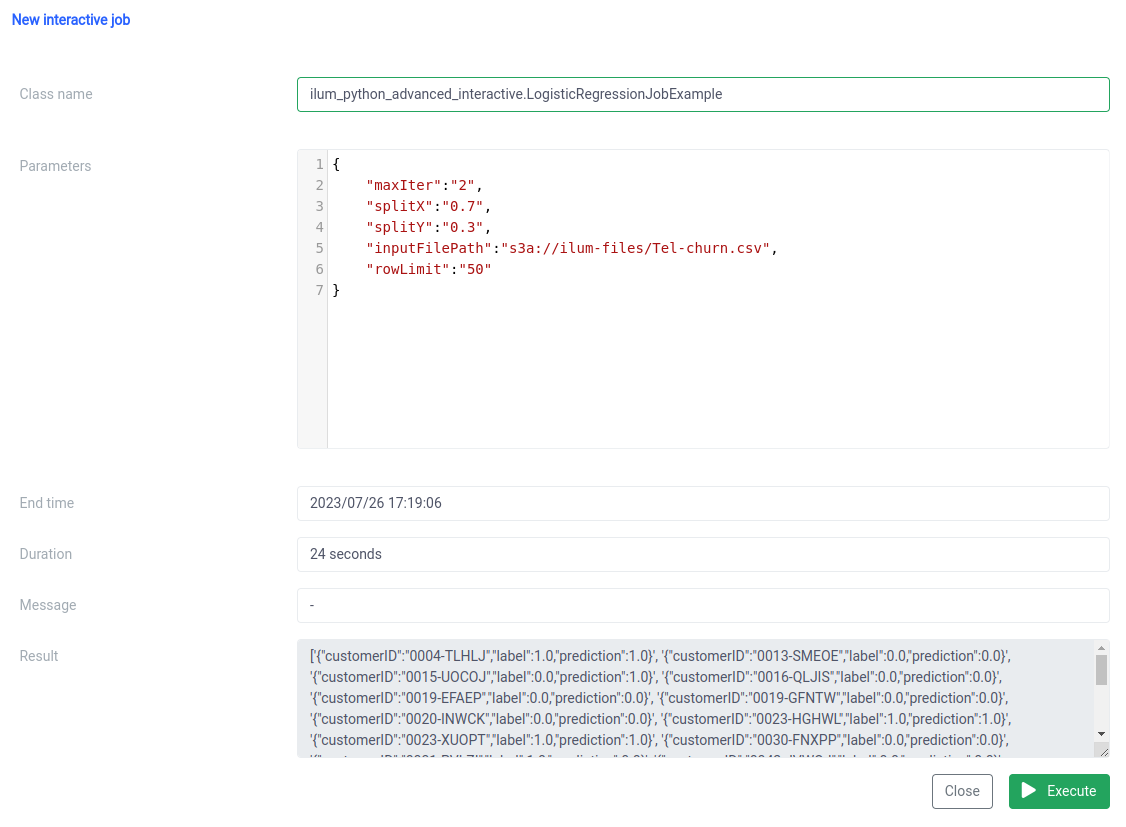
Passaggio 3: Trasformare il tuo lavoro Spark in un microservizio
I microservizi apportano un cambiamento di paradigma dalla tradizionale struttura di applicazioni monolitiche a un approccio più modulare e agile. Suddividendo un'applicazione complessa in piccoli servizi a regime di libero accoppiamento, diventa più facile creare, gestire e scalare ogni servizio in modo indipendente in base a requisiti specifici. Se applicato al nostro processo Spark, ciò significa che potremmo creare un solido servizio di elaborazione dati che potrebbe essere scalato, gestito e aggiornato senza influire su altre parti del nostro stack di applicazioni.
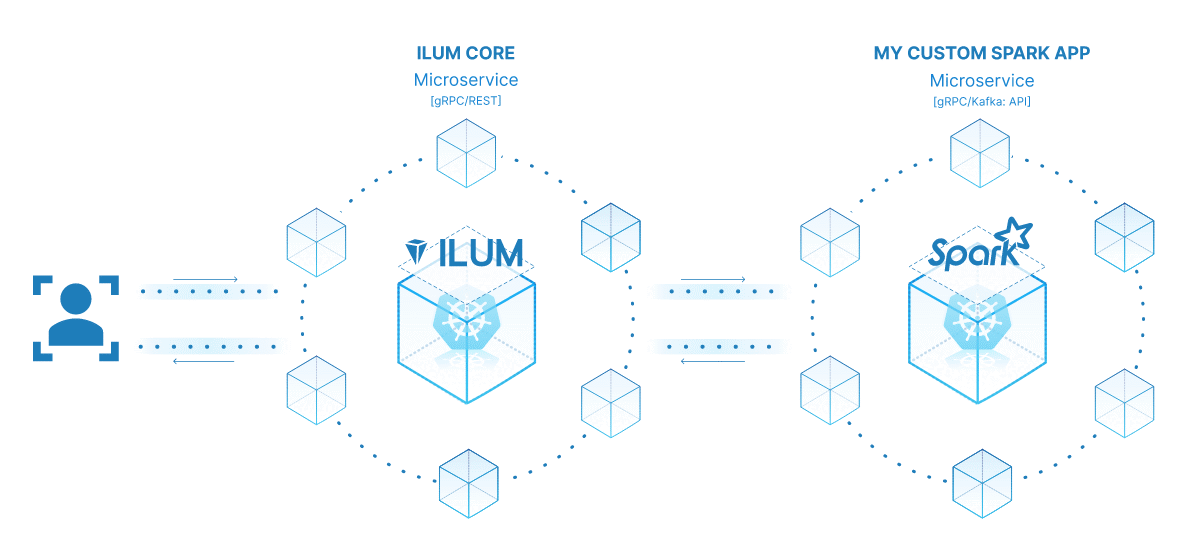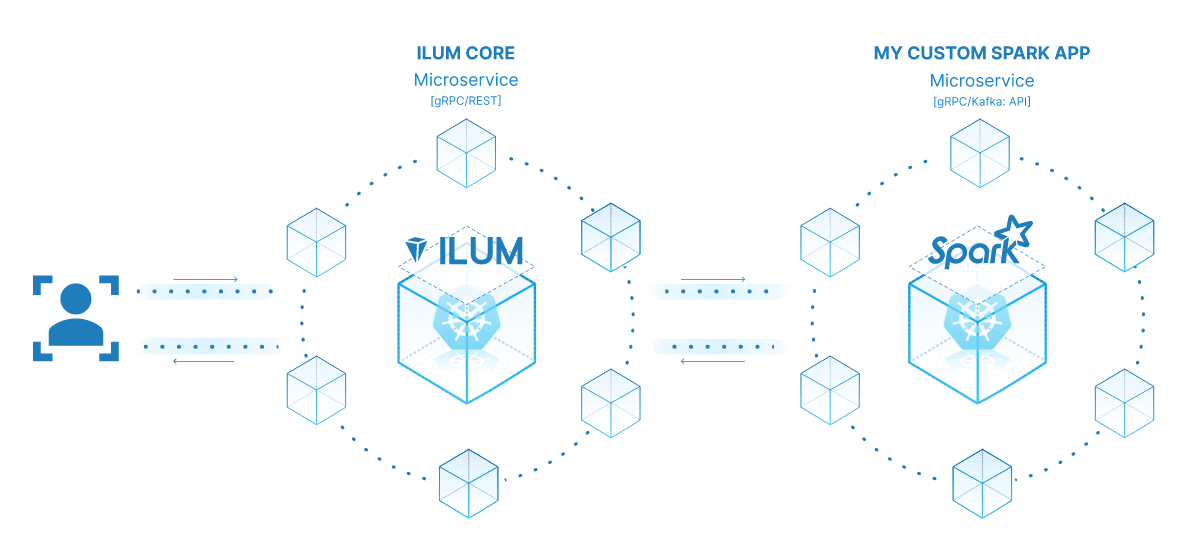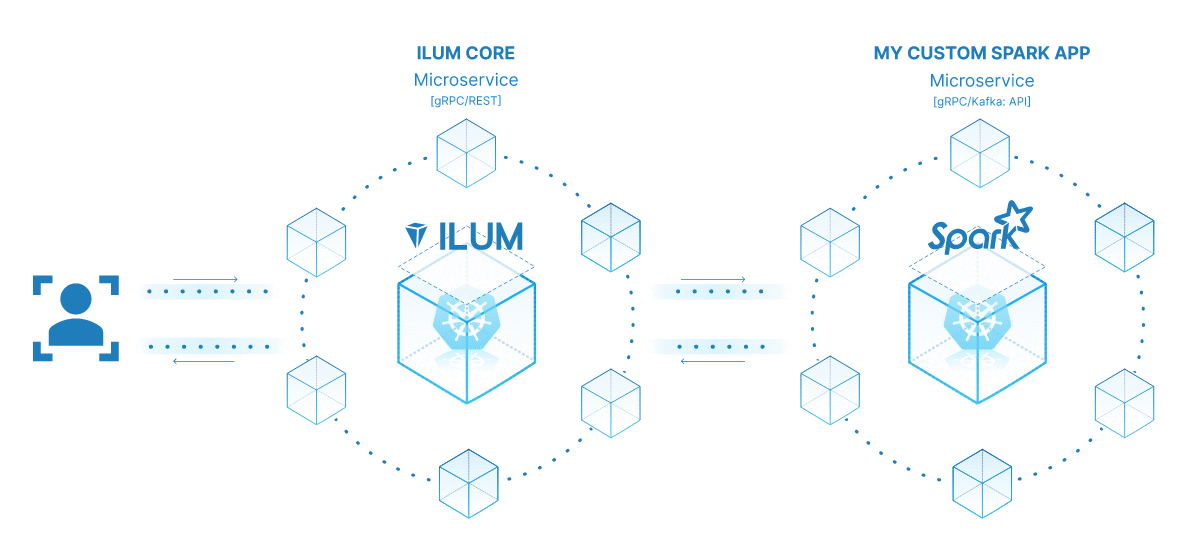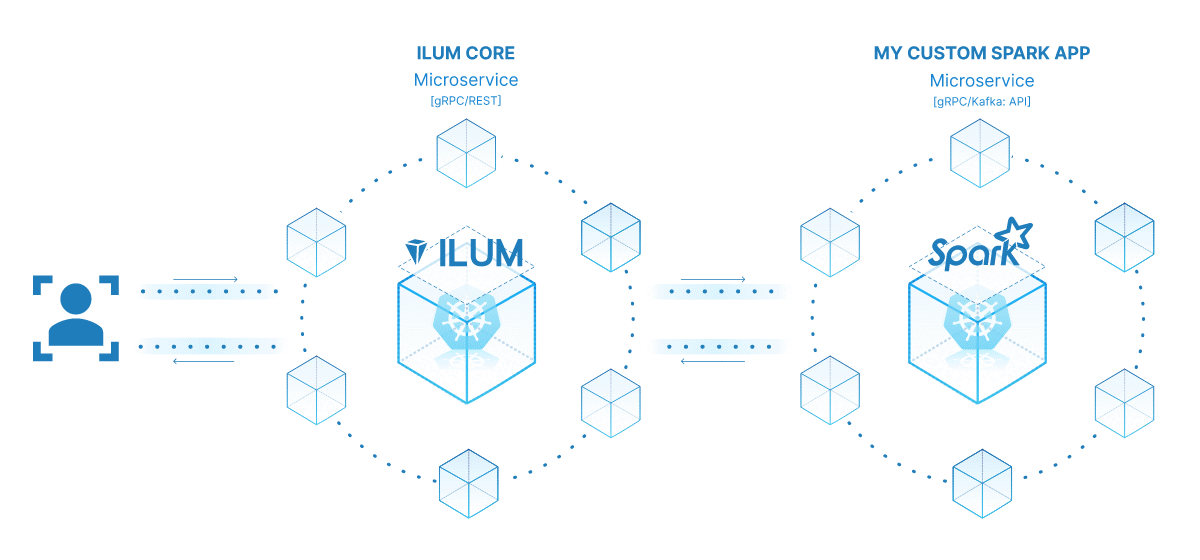
La potenza di trasformare il tuo processo Spark in un microservizio risiede nella sua versatilità, scalabilità e capacità di interazione in tempo reale. Un microservizio è un componente distribuibile in modo indipendente di un'applicazione che viene eseguito come processo separato. Comunica con altri componenti tramite API ben definite, offrendoti la libertà di progettare, sviluppare, distribuire e scalare ogni microservizio in modo indipendente.
Nel contesto di Ilum, un processo Spark interattivo può essere considerato come un microservizio. Il metodo 'run' del processo funge da endpoint API. Ogni volta che chiami questo metodo tramite l'API di Ilum, stai effettuando una richiesta a questo microservizio. Questo apre la possibilità di interazioni in tempo reale con il tuo lavoro Spark.
È possibile effettuare richieste al microservizio da varie applicazioni o script, recuperando i dati ed elaborando i risultati in tempo reale. Inoltre, offre l'opportunità di creare architetture più complesse e orientate ai servizi per le pipeline di elaborazione dei dati.
Uno dei vantaggi principali di questa configurazione è la scalabilità. Tramite l'interfaccia utente o l'API Ilum, è possibile aumentare o diminuire il processo (microservizio) in base al carico o alla complessità computazionale. Non devi preoccuparti della gestione manuale delle risorse o del bilanciamento del carico. Il bilanciatore di carico interno di Ilum distribuirà le chiamate API tra le istanze del tuo processo Spark, garantendo un utilizzo efficiente delle risorse.
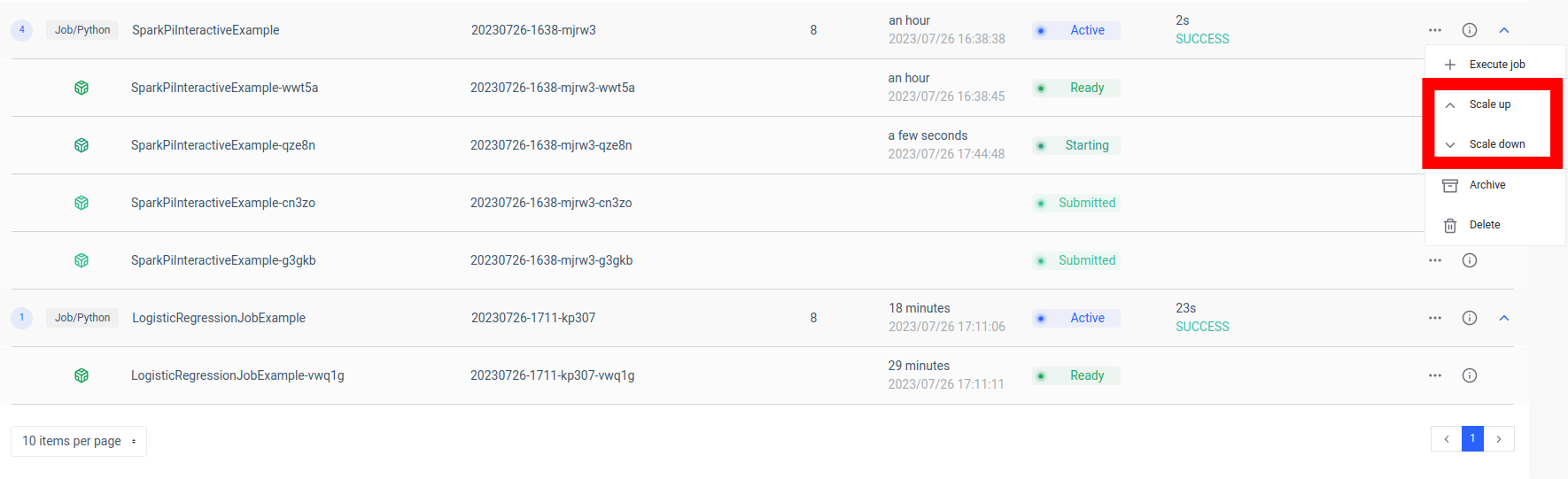
Tenere presente che il tempo di elaborazione effettivo del processo dipende dalla complessità del processo Spark e dalle risorse ad esso allocate. Tuttavia, con la scalabilità fornita da Kubernetes, è possibile aumentare facilmente le risorse man mano che i requisiti del processo aumentano.
Questa combinazione di Ilum, Apache Spark e microservizi offre un modo nuovo e agile di elaborare i dati, in modo efficiente, scalabile e reattivo!

Il punto di svolta nell'architettura dei microservizi dei dati
Abbiamo fatto molta strada da quando abbiamo iniziato questo percorso di trasformazione di un semplice processo Python Apache Spark in un microservizio completo utilizzando Ilum. Abbiamo visto quanto sia stato facile scrivere un processo Spark, adattarlo per funzionare in modalità interattiva e, infine, esporlo come microservizio con l'aiuto della robusta API di Ilum. Lungo il percorso, abbiamo sfruttato la potenza di Python, le funzionalità di Apache Spark e la flessibilità e la scalabilità di Ilum. Questa combinazione non solo ha trasformato le nostre capacità di elaborazione dei dati, ma ha anche cambiato il modo in cui pensiamo all'architettura dei dati.
Il viaggio non si ferma qui. Con il pieno supporto di Python su Ilum, si apre un nuovo mondo di possibilità per l'elaborazione e l'analisi dei dati. Mentre continuiamo a costruire e migliorare Ilum, siamo entusiasti delle possibilità future che Python offre alla nostra piattaforma. Crediamo che con Python e Ilum insieme, siamo solo all'inizio della ridefinizione di ciò che è possibile nel mondo dell'architettura dei microservizi di dati.
Unisciti a noi in questo entusiasmante viaggio e diamo forma insieme al futuro dell'elaborazione dei dati!